linux文件系统
在linux操作系统上,一 切都是文件。除了普通文件,还包括:目录,符号链接,IPC Endpoints(如pipe,unix socket)和设备文件(块设备,字符设备)。
存取文件,一般都是保存在普通的磁盘上,通过电磁变换实现文件的读写。所以,先从磁盘说起。
磁盘物理结构

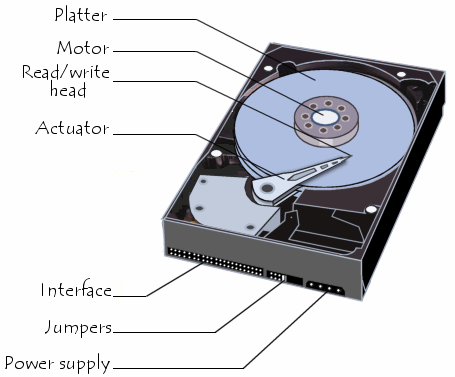
磁盘面: 磁盘是由一叠磁盘面组成磁头(Heads): 每个磁头对应一个磁盘面,负责该磁盘面上的数据的读写。磁道(Track):每个盘面会围绕圆心划分出多个同心圆圈,每个圆圈叫做一个磁道。柱面(Cylinders):所有盘片上的同一位置的磁道组成的立体叫做一个柱面。扇区(Sector):以磁道为单位管理磁盘仍然太大,所以计算机前辈们又把每个磁道划分出了多个扇区
可以使用
fdisk -l命令查看磁盘的物理信息。
磁盘IO时的过程
- 首先是磁头径向移动来寻找数据所在的磁道。这部分时间叫寻道时间
- 找到目标磁道后通过盘面旋转,将目标扇区移动到磁头的正下方。
- 向目标扇区读取或者写入数据。到此为止,一次磁盘IO完成。
- 单次磁盘IO时间 = 寻道时间 + 旋转延迟 + 存取时间
对于旋转延时,现在主流服务器上经常使用的是1W转/分钟的磁盘,每旋转一周所需的时间为60*1000/10000=6ms,故其旋转延迟为(0-6ms)。
对于存取时间,一般耗时较短,为零点几ms。
对于寻道时间,现代磁盘大概在3-15ms,其中寻道时间大小主要受磁头当前所在位置和目标磁道所在位置相对距离的影响。
linux 文件系统层次
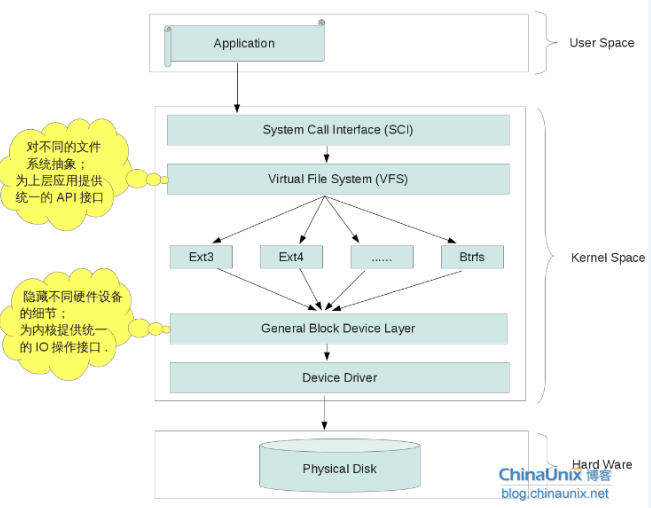
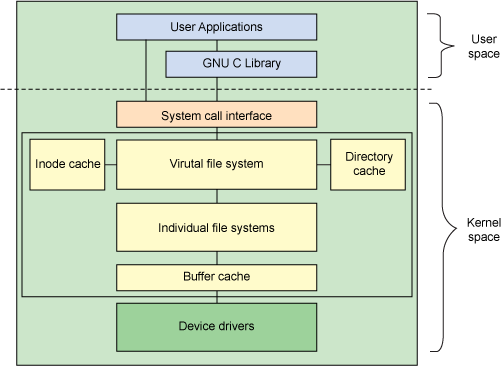
- 硬盘与硬盘驱动
硬盘硬件要与CPU交互,就需要通过硬盘驱动 - General Block Device Layer
常见的硬盘类型有PATA, SATA和AHCI等,但是不同的硬盘存储文件的结构、对基本块的定义等都不同,相应的驱动设备也会不同,不同的硬盘驱动会提供不同的IO接口,而该层就是将这些接口抽象,提供给内核通过的接口,方便管理,都一视同仁为块设备。 - 文件系统
linux常见的文件系统有ext2、ext4,现在新一代的btrfs也快出来了。那么,文件系统到底是什么?有什么作用?
磁盘分区之后一般都需要格式化(format),之后操作系统才能够正常使用这个硬盘存储信息。为什么需要格式化呢?因为每种操作系统配置的文件属性(也可以叫做定义的文件元数据)/权限并不相同,为了存放这些文件需要的数据,就需要将硬盘格式化,成为操作系统能够利用的文件系统格式(filesystem)。
比如常见的window中的NTFS文件系统,在linux上就不认,因为linux使用的是Ext2 (Linux second extended file system, ext2fs)或现在的Ext4。- 虚拟文件系统(VFS)
Virtual File System主要是对不同文件系统的抽象,不再需要关心不同文件系统提供的不同API了,为上层提供统一的API接口。我们只需要关心操作如:mount/umount、open/close、mkdir等。
- 虚拟文件系统(VFS)
可通过fdisk -l 查看各个磁盘的信息
文件存储结构
块(Block)
文件是存储在硬盘上的,硬盘的最小存储单位叫做扇区(Sector)。每个扇区固定存储512字节(也就是0.5KB)
操作系统再读取硬盘的时候,不会一个个扇区地读,效率太低,会一次性读取一个块(block)。这种由多个扇区组成的块,是文件存取的最小单位。块的大小,常见的有1、2、4KB。可以通过/sbin/tune2fs -l /dev/vdb|grep "Block size"查看某个文件存储系统的块大小。
inode块是用来存储文件内容的,inode是文件的索引,包含了文件的各种元数据inode包含的文件元数据有:
- 文件字节数
- 文件拥有者 User Id
- 文件的 Group Id
- 文件读写和执行的权限
- 文件时间戳,有ctime-更改时间,mtime-修改时间,atime-打开的时间
- 连接数,有多少个文件名指向这个inode(硬链接)
- 文件数据块的位置
通过指令
stat filename查看某文件的元数据信息。elixir的File.Stat就是描述的该数据结构,
inode也会消耗磁盘空间,每一个inode一般固定占用128字节。可以通过命令dumpe2fs -h /dev/vdb | grep "Inode size"查看大小。在硬盘格式化的时候,操作系统会将硬盘分成两个区域,一个数据区,存放文件数据;另一个就是inode区,存放inode table所包含的信息。
硬盘在格式化完成的时候,就已经确定了inode的总数和block的总数,一般是每1KB或者2KB就设置一个inode。假定在一块1G的硬盘中,每个inode节点大小为128字节,每1KB就设置一个inode,那么inode table大小就会到达128M,占总容量的12.8%。可以通过df来查看块的使用情况;df -h查看硬盘空间的使用情况;df -i查看inode的使用情况。
每一个文件都会对应一个inode,可以通过inode number查找到某个文件,可通过ls -i filename查看文件的inode number也有可能发生inode已经用光,但是硬盘还没有满的情况,这种情况,也是无法创建新文件的。
根据路径找文件
以查找文件/home/wyj/test.file为例。
假设根目录的inode number=2,根据INode Table查找到根目录这个文件的元数据,并找到存储目录信息的块的位置。
目录也是文件。也有块存着该文件的信息,目录文件的块中存的是一系列
目录项(dirent)的列表。目录项,就是所包含的文件名,以及该文件名对应的inode number
比如说,督导的数据块的结构如下:1
2
3 +----+-----+-----------------------------------------+
#2 |. 2 |.. 2 | home 5 | usr 9 | tmp 11 | etc 23 | ... |
+----+-----+-----------------------------------------+
通过目录下home目录的名字 home,找到对应的inode number是5,再找到对应的数据块的内容结构。同样的找到目录名字为wyj的目录对应的indoe number,最后找到文件test.file的inode number,根据INode Table找到文件所在的数据块,读取文件内容。下面的图形象的表示了,在磁盘中读取某个文件内容的过程:
而且,通过INode Table查找inode number找到的inode文件元数据中,也包含了权限信息,该权限信息也决定了是否有操作该文件的权限。
- 目录的inode权限,决定了是否有权限修改,移动,删除该目录,以及目录下的文件。
- 文件的inode权限,决定了是否有权限读取或者修改该文件的内容。
那么上面一直提到的INode Table是从哪来的呢?
详细的文件系统介绍
以ext2文件系统为例,其文件系统结构图示意如下: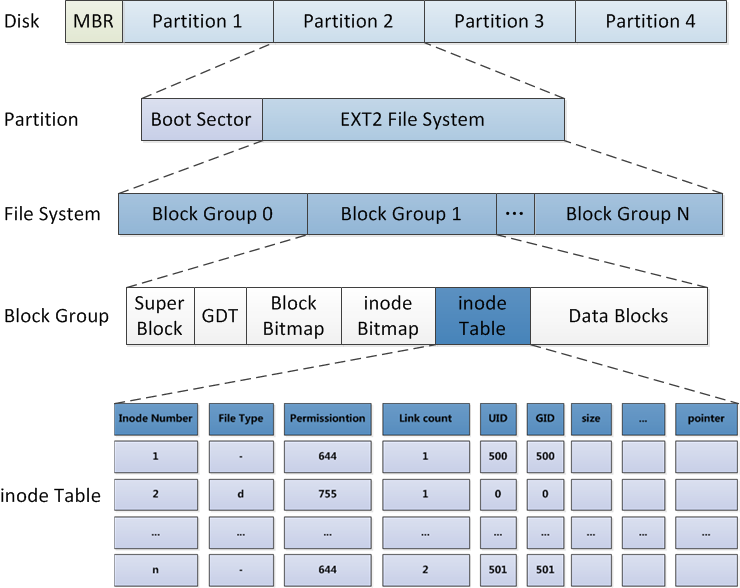
- 一块硬盘会被划分成多个分区
- 每个分区挂载着相应的文件系统具体实现,如ext2
- 为了减少需要管理的block的数量,在ext2文件系统产生了块组的概念。每个块组包含多个block,并且有独立的superblock和inode。
名词说明:
Boot Sector: 即引导扇区。包括:本分区的操作系统类型,数据区大小,根目录区允许的最大目录项Super Block: 超级块。定义了文件系统的静态结构,包括:分区中每个block的大小,分区中block group的数目,以及每个block group中有inode等。每个block group不一定都有超级块,其他block group中的超级块仅仅是block group 0中超级块的一个拷贝,以备当block group 0中的超级块损坏时可以对其进行恢复。Linux启动时,block group 0中的超级块的内容会被读入到内存中。GDT: 组描述符表。记录了块位图(Block Bitmap)所在块的块号,inode位图(inode Bitmap)所在块的块号,inode表(inode Table)所在块的起始块号,本组空闲块的个数等组内信息。文件系统根据这些信息来查找数据块位图,索引结点位图,索引结点表的位置Block Bitmap: Ext2文件系统的数据块位图。其中每一位对应了一个数据块,某一位上位0时表示该位所对应的数据块空闲,反之表示该位所对应的数据块已经被分配。Data Block Bitmap占了1个块的空间,因此,一个组中的数据块的个数就已经决定了。如果每个块为b-byte,那么该Group Block就有8b个块,可以存放(8b)*b字节的数据Inode Bitmap: inode节点位图。其工作方式跟Block Bitmap相同,只不过代表的是Inode的使用情况,每个位代表一个inode,如果是1则表示被使用,为1表示空闲Inode Table: 存储inode number对应文件的元信息,包括:文件类型,权限位,链接数(有多少文件名指向这个inode),文件数据块的位置。
B+树与B+树在文件系统、数据库索引中的应用
B树 B-树 B+树
B树就是普通的二叉搜索树(binary search tree)
特点:
- 所有非叶子结点至多拥有两个儿子(Left和Right);
- 所有结点存储一个关键字;
- 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
通常如下图所示: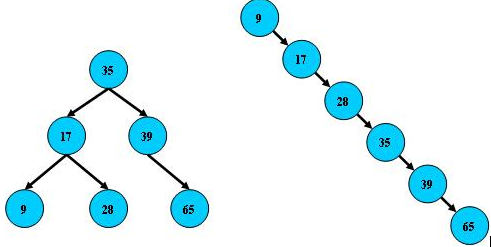
通常B树的搜索效率是能达到二分查找,但是也有可能出现后面的情况,这时候B树的检索效率就是O(n)了,和链表一样。
所以后来有了平衡二叉树。平衡二叉树保证了搜索效率达到二分查找。
还有一种平衡二叉树,是红黑树,他的查找效率也能保证达到二分的效率。为什么有了平衡二叉树还要有红黑树呢?因为平衡二叉树要维持平衡需要在插入删除操作的时候,通过左旋、右旋等操作不断的调整树的结构,保证二叉树的平衡,红黑树也是这样,但是红黑树的结构大大降低了插入或者删除时,旋转操作的次数,所以一般用红黑树比较多,比如说java中jdk提供的标准类(忘了是什么了额)就是使用的红黑树。
B-树是一种多路搜索树(并不是二叉的),M表示数的深度,只有根节点是1。
- 定义任意非叶子结点最多只有M个儿子;且M>2
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];
- 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
- 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
- 所有叶子结点位于同一层;
如M=3: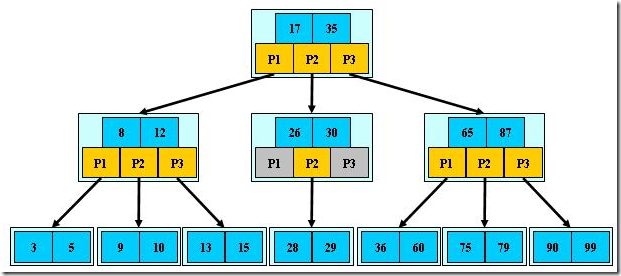
B-树的搜索:从根节点开始,对节点内的关键字(有序的,我自己猜测可能是数组的结构,因为大小是固定的?)序列进行二分查找,如果命中,则结束;否则进入查询关键字所属范围的儿子节点,重复前面的过程,直到所随影的儿子指针为空(没找到),或者是叶子节点(也就是找到了)
B-树的特性(可以与后面的B+树对比来看):
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
因为限制了除了根节点外的非叶子节点,至少含有M/2个儿子,所以确保了节点的利用率,也降低了树的高度,经过数学推导计算,B-树的搜索性能总是等价于二分查找。
B+树是B-树的变体,是一种多路搜索树。
- 其定义基本与B-树同,除了:
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
如M=3: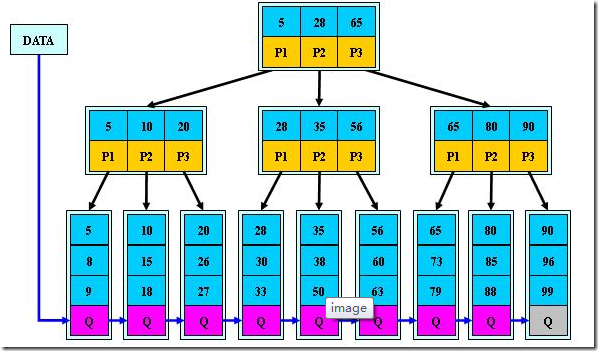
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
以上参考自:理解b树、b+、b-树
B+树 文件系统索引和数据库索引
优势:
B+树空间利用率更高,减少IO次数
一般来说,索引本身也很大,不会全部存储在内存中,往往以索引文件的形式存储在磁盘上,所以索引查找过程会产生磁盘IO消耗,而且B+树内部节点只作为索引使用,不像B-树那样每个节点还需要存储硬盘也就是指向某条记录的指针。也就是说,B+树中,每个非叶子节点没有指向某个关键字具体信息的指针,所以每个节点可以存放更多的关键字数量,一次的IO操作读入需要查找的关键字更多,减少了IO操作。
比如说,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内 部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就 是 盘片旋转的时间)增删文件(节点)时,效率更高
B+树叶子节点包含所有的关键字,并以有序链表结构存储,这样很好的提高了增删效率B+树查询效率更稳定
B+树每次查询过程,都需要比那里从根节点到叶子节点的某条路径,所有关键字的查询路径相同,每次查询效率相当。而且,B+树的每个节点存储了M/2-M个关键字,所以也保证了深度不会太大,也就是保证了查询效率。
局部性原理与磁盘预读磁盘的存取比内存要慢很多,往往是内存的几百分之一,为了提高效率就要减少磁盘IO。所以在磁盘读取的时候,那怕只是一个字节,磁盘也会读取从这个位置开始向后一定的长度的数据放入内存,这样做是因为著名的局部性原理。当一个数据需要被用到时,其附近的数据也通常马上会被用到;程序运行期间所需要的数据通常比较集中。
预读的长度,一般为页(page)的整数倍。页是计算机管理存储器的逻辑快,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。所以一般的B+树的节点大小一般都设置为1一个页的大小,这样每个节点只需要一次IO就可以完全载入。
以上参考自:
分布式文件系统 - FastDFS 配置 Nginx
了解FastDFS原理与过程
Linux文件系统详解
Linux文件系统如何进行文件存取
Linux的inode的理解
inode大杂烩
鸟哥私房菜inode的介绍
用FastDFS一步步搭建文件管理系统
